检测图像中的人体姿势
检测图像中的人体姿势
通过使用PoseNet模型分析图像来定位人和他们的身体姿势。
概述
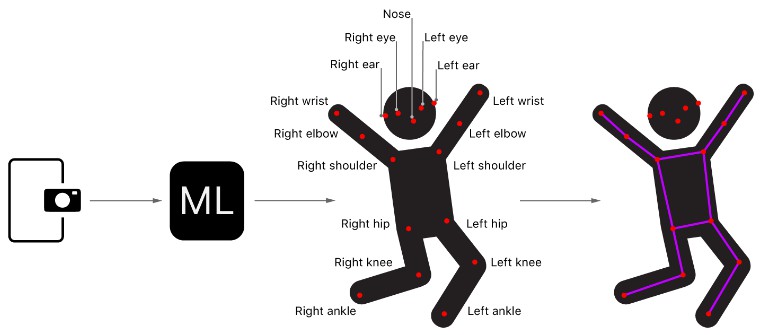
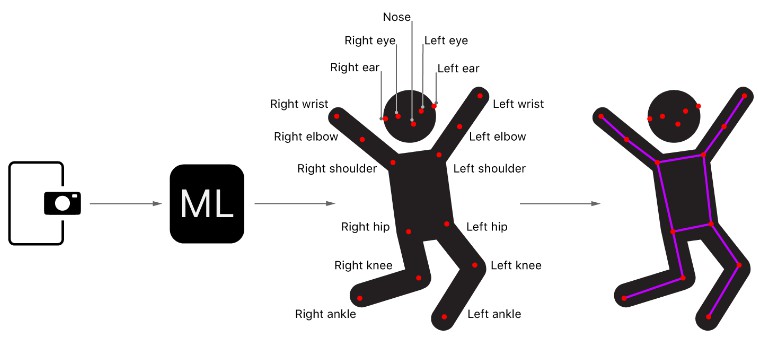
此示例项目提供了一个使用第三方 Core ML 模型 PoseNet 从使用相机捕获的帧中检测人体姿势的说明性示例。PoseNet 模型可检测 17 种不同的身体部位或关节:眼睛、耳朵、鼻子、肩膀、臀部、肘部、膝盖、手腕和脚踝。这些关节共同形成一个姿势。

该示例查找图像中每个人的 17 个关节的位置,并在它们上面绘制一个线框姿势。
- 【注】从 iOS 14 和 macOS 11 开始,Vision 增加了检测人体姿势的功能。有关详细信息,请参阅检测图像中的人体姿势。
配置捕获会话
该示例首先使用 AVCaptureSession 从设备的内置相机获取图像(请参阅设置捕获会话)。
if captureSession.isRunning {
captureSession.stopRunning()
}
captureSession.beginConfiguration()
captureSession.sessionPreset = .vga640x480
try setCaptureSessionInput()
try setCaptureSessionOutput()
captureSession.commitConfiguration()
Acquire the Captured Image
A video capture session sends each image to the captureOutput(_:didOutput:from:) method of the class, where the app converts the received CMSampleBuffer into a CGImage before passing it to the delegate assigned to the object.VideoCaptureVideoCapture
// Attempt to lock the image buffer to gain access to its memory.
guard CVPixelBufferLockBaseAddress(pixelBuffer, .readOnly) == kCVReturnSuccess
else {
return
}
// Create Core Graphics image placeholder.
var image: CGImage?
// Create a Core Graphics bitmap image from the pixel buffer.
VTCreateCGImageFromCVPixelBuffer(pixelBuffer, options: nil, imageOut: &image)
// Release the image buffer.
CVPixelBufferUnlockBaseAddress(pixelBuffer, .readOnly)
DispatchQueue.main.sync {
delegate.videoCapture(self, didCaptureFrame: image)
}
Prepare the Input for the PoseNet Model
After receiving the captured image, the app wraps it in an instance of , a custom feature provider, to resize the image to the specified size.PoseNetInput
// Wrap the image in an instance of PoseNetInput to have it resized
// before being passed to the PoseNet model.
let input = PoseNetInput(image: image, size: self.modelInputSize)
Pass the Input to the PoseNet Model
The sample app then proceeds to pass the input to the PoseNet’s prediction function to obtain its outputs, which the app uses to detect poses.
guard let prediction = try? self.poseNetMLModel.prediction(from: input) else {
return
}
Next, the sample app wraps the PoseNet model outputs in an instance of , along with the model’s input size and output stride, before passing it back to the assigned delegate for analysis.PoseNetOutput
let poseNetOutput = PoseNetOutput(prediction: prediction,
modelInputSize: self.modelInputSize,
modelOutputStride: self.outputStride)
DispatchQueue.main.async {
self.delegate?.poseNet(self, didPredict: poseNetOutput)
}
Analyze the PoseNet Output to Locate Joints
The sample uses one of two algorithms to locate the joints of either one person or multiple persons. The single-person algorithm, the simplest and fastest, inspects the model’s outputs to locate the most prominent joints in the image and uses these joints to construct a single pose.
var pose = Pose()
// For each joint, find its most likely position and associated confidence
// by querying the heatmap array for the cell with the greatest
// confidence and using this to compute its position.
pose.joints.values.forEach { joint in
configure(joint: joint)
}
// Compute and assign the confidence for the pose.
pose.confidence = pose.joints.values
.map { $0.confidence }.reduce(0, +) / Double(Joint.numberOfJoints)
// Map the pose joints positions back onto the original image.
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
return pose
The multiple-person algorithm first identifies a set of candidate root joints as starting points. It uses these root joints to find neighboring joints and repeats the process until it has located all 17 joints of each person. For example, the algorithm may find a left knee with a high confidence, and then search for its adjacent joints, the left ankle and left hip.
var detectedPoses = [Pose]()
// Iterate through the joints with the greatest confidence, referred to here as
// candidate roots, using each as a starting point to assemble a pose.
for candidateRoot in candidateRoots {
// Ignore any candidates that are in the proximity of joints of the
// same type and have already been assigned to an existing pose.
let maxDistance = configuration.matchingJointDistance
guard !detectedPoses.contains(candidateRoot, within: maxDistance) else {
continue
}
var pose = assemblePose(from: candidateRoot)
// Compute the pose's confidence by dividing the sum of all
// non-overlapping joints, from existing poses, by the total
// number of joints.
pose.confidence = confidence(for: pose, detectedPoses: detectedPoses)
// Ignore any pose that has a confidence less than the assigned threshold.
guard pose.confidence >= configuration.poseConfidenceThreshold else {
continue
}
detectedPoses.append(pose)
// Exit early if enough poses have been detected.
if detectedPoses.count >= configuration.maxPoseCount {
break
}
}
// Map the pose joints positions back onto the original image using
// the pre-computed transformation matrix.
detectedPoses.forEach { pose in
pose.joints.values.forEach { joint in
joint.position = joint.position.applying(modelToInputTransformation)
}
}
return detectedPoses
Visualize the Detected Poses
For each detected pose, the sample app draws a wireframe over the input image, connecting the lines between the joints and then drawing circles for the joints themselves.

let dstImageSize = CGSize(width: frame.width, height: frame.height)
let dstImageFormat = UIGraphicsImageRendererFormat()
dstImageFormat.scale = 1
let renderer = UIGraphicsImageRenderer(size: dstImageSize,
format: dstImageFormat)
let dstImage = renderer.image { rendererContext in
// Draw the current frame as the background for the new image.
draw(image: frame, in: rendererContext.cgContext)
for pose in poses {
// Draw the segment lines.
for segment in PoseImageView.jointSegments {
let jointA = pose[segment.jointA]
let jointB = pose[segment.jointB]
guard jointA.isValid, jointB.isValid else {
continue
}
drawLine(from: jointA,
to: jointB,
in: rendererContext.cgContext)
}
// Draw the joints as circles above the segment lines.
for joint in pose.joints.values.filter({ $0.isValid }) {
draw(circle: joint, in: rendererContext.cgContext)
}
}
}